














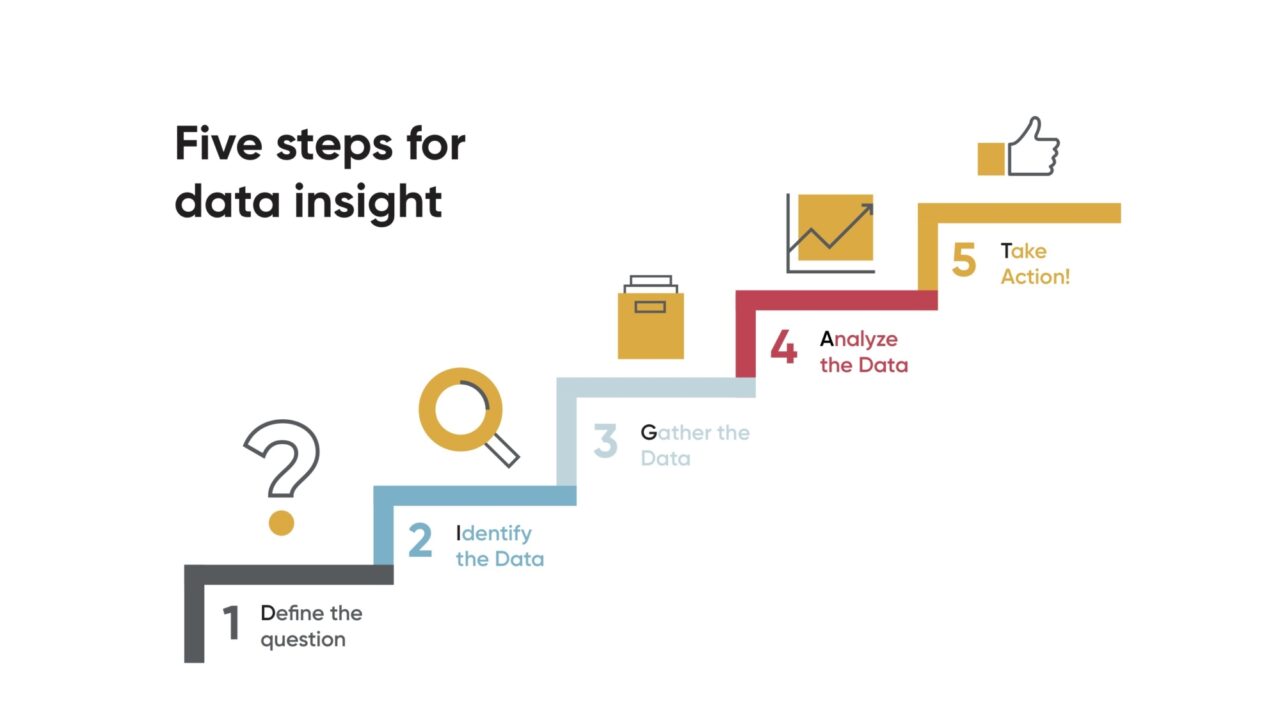
In part one of my series on turning educational data into actionable insight, I described how important data has become for educators and addressed the reality that for many people in education, it is difficult to know how to get started. As a roadmap for this journey to data insight, I described a five-step process:
The first step in the process is critical—deciding what questions to answer in order to gather the right data. This step sets the stage for everything that follows. Some examples of questions that educators might want to answer might include:
- Which students are most at risk of falling behind in a given subject area?
- How effective are specific interventions on a sub-group of students?
- How predictive are formative assessment results of scores on benchmark tests?
- Which teachers or school leaders could benefit from additional coaching?
From Data to Decisions
The value of data is when it is turned into information that can be acted upon. This five-step process—which can be remembered by the acronym DIG-AT—covers the full cycle from asking a question through taking action. Once the first step has been completed and the question has been identified, then the next step is to determine what data is necessary to answer the question and figure out where, if anywhere, it currently exists.
Step Two: Identifying the Data
In part one, we talked about the different types of information that can be created from data, including information about learner engagement and usage, pedagogical fidelity, and growth. To identify the data, you need to get even more specific. If the question is about growth—for instance, “what groups of students in a school showed the greatest gains in reading proficiency?”—then the data necessary for the analysis might be student-level Lexile® scores on a standardized reading comprehension assessment conducted at two different points of time. For each student, in addition to a score on each of at least two assessments, you would want a unique identifier, and would need to know the characteristics necessary for the grouping, such as grade level, SES, teacher, etc.
Determining the data that is necessary is only half of the work required—the source of the data also has to be identified. In an educational system, data lives in many different places, such as the student information system (SIS) and the learning management system (LMS), and likely many others. It may also be found that the necessary data does not exist anywhere and a process needs to be put in place to collect and/or generate the required data, in which case the analysis has to be put on hold until the data is available. This data identification process can be facilitated by creating a data identification matrix similar to this:
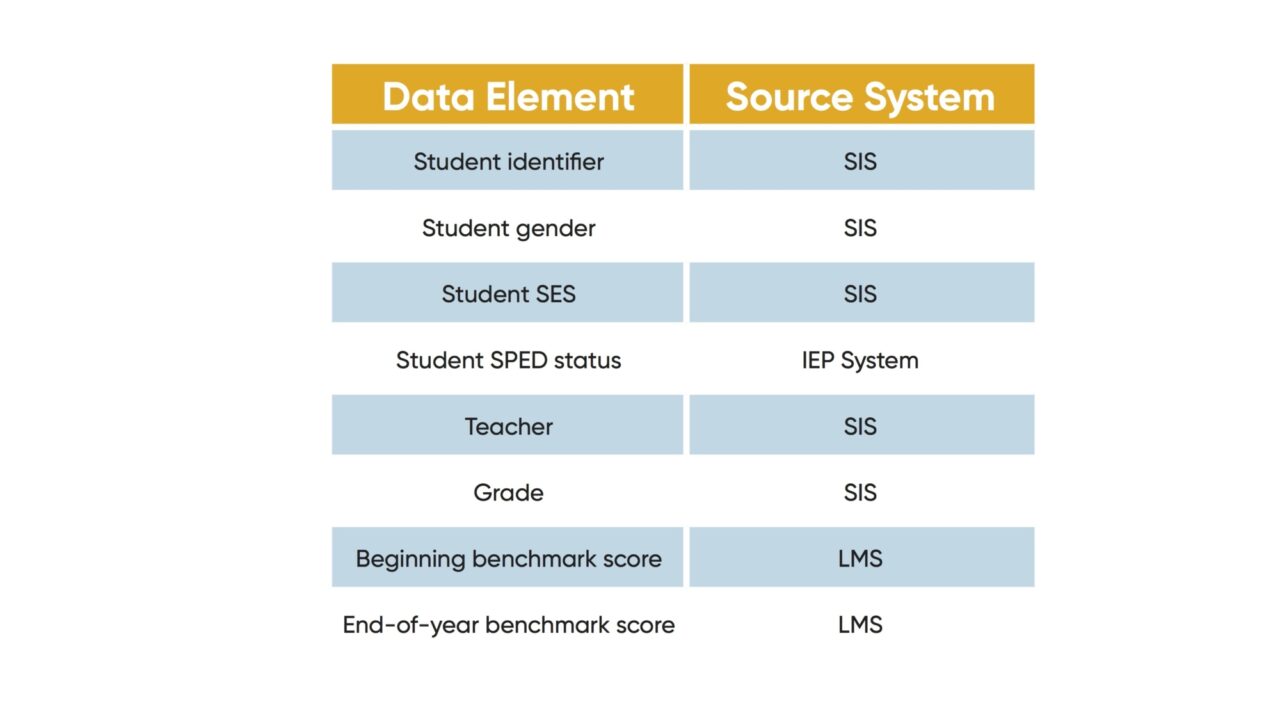
Now that the data has been identified and located, the next step is to go get it.
Step Three: Gathering the Data
There are actually three different sub-activities required to gather the data that was identified in step two. First, a location has to be identified for where the data will be stored—ideally a secure, durable environment where the data can be safely maintained and access can be carefully controlled. Next, processes have to be put in place to capture the data from the source system and place it in the identified location. Finally, the data has to be effectively organized so it can be accurately identified, and in many cases it will need to be “cleaned” or “transformed” so that it can be properly analyzed. This step in the data insight process, while not necessarily challenging from an analytical or cognitive standpoint, typically requires the greatest amount of effort if it is to be performed effectively.
Determining where the data is to be stored after it has been identified and accessed requires a great deal of forethought and planning. A district may already have a functioning data warehouse of some sort, which might make this process easy. However, traditional data warehouses can be expensive to build, complicated to maintain, and difficult to adapt to changing needs. Conversely, some districts end up with data being stored all over the place—on different desktop and laptop computers, or on storage attached to servers in the data center. Having data distributed across different platforms can introduce security risks, and it can also make it difficult to do the necessary analysis. But there are now emerging some solutions for data storage and management that can allow a district to safely, securely, and inexpensively create a data storage environment “in the cloud” that is much easier and quicker to implement and enhance. I will discuss some of these new models in a future posting—if you want a head-start, read this article.
While data can help users answer questions, its real power exists when advanced analytics are used to help make decisions that enable people to perform better and achieve more.
Next time, we’ll look at how to conduct the analysis that turns the data into actionable insight.
Lexile® is a trademark of MetaMetrics, Inc., and is registered in the United States and abroad.


